
Powerful new capabilities emerge across the community
Organizations across industry and government provided powerful new capabilities and streamlined workflows.
In August, Intelligent Light of New Jersey delivered its IntelliTwin and Kombyne tools to the U.S. Air Force Research Laboratory and U.S. Air Force Academy. Developed under a Direct-to-Phase II Small Business Innovative Research project, the software provides optimized and streamlined simulation and postprocessing workflows, which allows users more time for learning and innovating. The web-based point-and-click interface allows engineers to rapidly set up multiple cases, execute them on remote high-performance computing systems, and monitor and visualize the results in real time. The workflow has already made an impact on the computational aerodynamics curriculum at the academy, allowing for deeper discussions and what-if analyses in projects conducted throughout the semester.
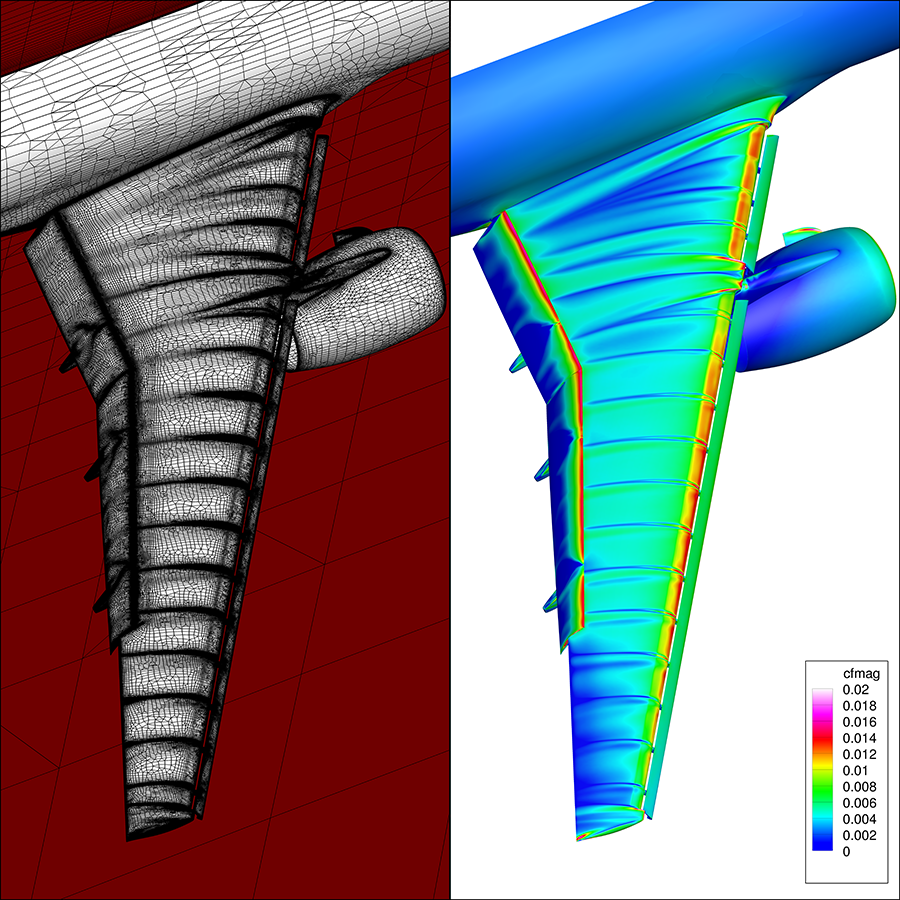
The workflow to generate structured grid systems for complex geometries is notorioudrsly time-consuming. In June, researchers at NASA’s Ames Research Center in California demonstrated for the first time the full automation of structured grid preprocessing, spanning the workflow from input geometry to the start of the flow solution computation. The automated steps included surface mesh generation, volume mesh generation, domain connectivity and solver input deck creation. As a result, the meshing turnaround time was reduced from two days to about two hours for simple cases and two weeks to about two days for more complex cases. The resulting aerodynamic loads and convergence behavior of flow solutions computed on the automatic meshes are comparable to data computed using other methods.
In August, Helden Aerospace of Georgia reported on numerous grid studies as part of the 5th AIAA CFD High Lift Prediction Workshop. The studies were completed via a unique source-based unstructured mesh adaptation capability that identifies areas for refinement via flow solutions. These flow features, or adjoint-based sources, then help engineers generate a new high-quality mesh, with targeted refinement of the critical flow areas, without the potential loss in mesh quality possible with traditional cell subdivision approaches. When coupled with the company’s HeldenMesh grid generator, the new mesh adaptation workflow generated billion-cell meshes in under 10 minutes on a laptop. In all, 1,142 Navier-Stokes computational fluid dynamics meshes were generated during the workshop — some 1.04 trillion cells. These studies represent the type of critical grid studies needed to quantify the accuracy of advanced CFD methods and establish meshing best practices.
The U.S. Department of Defense’s High Performance Computing Modernization Program, HPCMP, continued to expand and maintain an extensive array of supercomputers, high-speed and secure networking, and software development for science and test activities conducted by all the military services. HPCMP is approaching 20 billion core-hours of supercomputing capacity, at multiple classification levels, across the department’s five supercomputing resource centers. Of particular note, in September, the “Carpenter” supercomputer at the Army’s Engineer Research and Development Center, an HPE Cray EX4000, was expanded to 313,344 cores.
Between January and August, HPCMP’s Computational Research and Engineering Acquisition Tools and Environments (CREATE) program released new versions of all products in its suite of simulation tools supporting air, land and sea vehicle acquisitions. A key thrust for the Kestrel fixed-wing and Helios rotary wing high-fidelity simulation tools was development of a performance-portable flow solver capable of executing on various types of either standard central processing units or general purpose graphics processing units. In January, the development team demonstrated one of the first-ever overset grid simulations in which the near-body unstructured solver, the background (off-body) Cartesian solver and the automatic domain connectivity operations were all executed on GPGPUs. Scalable performance was demonstrated on up to 100 GPGPUs.
Contributors: William Chan, Earl Duque and Rick Hooker
